はじめに
以前、Vim script で機械学習という記事を書いた事で、「Vim script で機械学習は可能」という事を皆さんにもご理解頂けたはずなので、今回は Vim script を使ってアヤメの品種分類をしたいと思います。
出典: https://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A4%E3%83%A1

iris.csv とは
アヤメは温帯に生息するおよそ150種類からなるアヤメ科の植物で、その多くは、がく片の長さ、がく片の幅、花弁の長さ、花弁の幅でその品種が分類できるそうです。この研究結果を UCI(カリフォルニア大学アーバイン校)がデータマイニングの検証用データとして iris.csvというファイル名で配布していて機械学習をやる方の間では有名なデータセットになっています1。iris.csvに含まれるのは、setosa、versicolor、virginica の3種で、150個のサンプルが含まれています。
出典: https://en.wikipedia.org/wiki/Iris_flower_data_set#cite_ref-fisher36_1-0
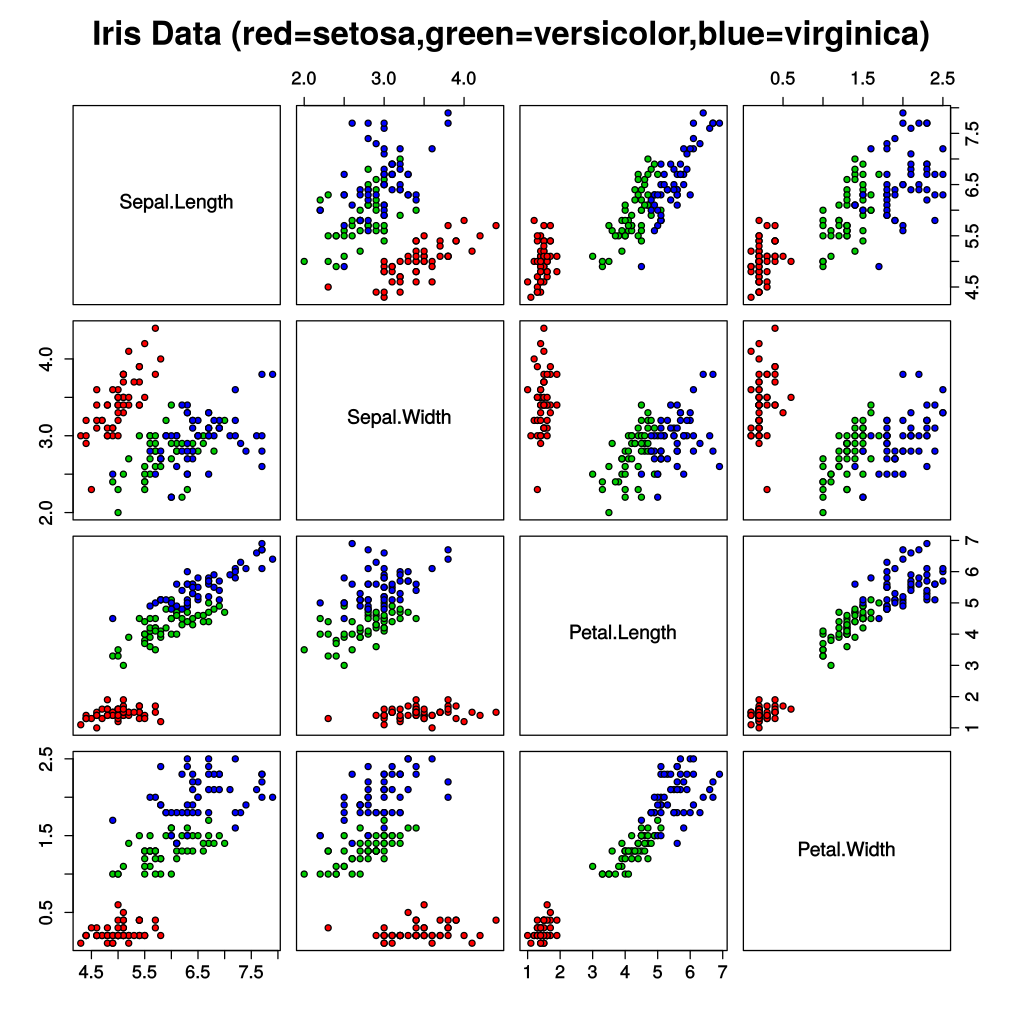
これは、がく片の長さ、がく片の幅、花弁の長さ、花弁の幅、それぞれをペアで図にした物ですが、これを見るだけでも個々の形容の属性値と品種に相関があるのが分かります。iris.csvは以下の内容で定義されています。
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm
5. class:
-- Iris Setosa
-- Iris Versicolour
-- Iris Virginica
SepalLength,SepalWidth,PetalLength,PetalWidth,Name
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
Vim script で分類しましょう
さっそく Vim script から CSV を読み込んでみます。Vim script にも浮動小数型があるのでファイルから文字列を読み込み、カンマで分割、数字で構成させているのであれば文字列評価で数値化します。
function!s:token(line) abort
return map(split(a:line,','),'v:val =~# "^[-+]\\?[0-9][.]\\?[0-9]*$" ? str2float(v:val) : v:val')endfunctionfunction!s:main() abort
letl:data = map(readfile('iris.csv'),'s:token(v:val)')[1:]endfunctionCSV の1~4カラム目が属性値、5カラム目が品種になるので分割します。
let[l:X,l:y]=[[],[]]forl:row inl:data
call add(l:X,l:row[:3])call add(l:y,l:row[4])endforBag of Words
品種名の一覧から品種名の一覧を作り、数値化(Bag of Words)します。
function!s:make_vocab(names) abort
letl:ns ={}forl:name ina:namesif!has_key(l:ns,l:name)letl:ns[l:name]=0.0+ len(l:ns)endifendforreturnl:ns
endfunctionfunction!s:bag_of_words(names, vocab) abort
return map(a:names,'(0.0 + a:vocab[v:val]) / len(a:vocab)')endfunctionletl:vocab =s:make_vocab(l:y)calls:bag_of_words(l:y,l:vocab)これで l:yが名称の一覧ではなく、品種名を示す値になった訳です。ロジスティック回帰を使うのですが、残念ながら Vim script には乱数を生成する機能がありません。Xorshift を扱う為の pull-requst を送ってはいますが、未だマージされていません2。
そこで疑似乱数生成機を作ります。以下は V8 で使われている George Marsaglia 氏の MWC アルゴリズムです。
" Random number generator using George Marsaglia's MWC algorithm.lets:hi=0lets:lo=0function!s:srand(seed)ifa:seed<0lets:hi=(a:seed-0x80000000) / 0x10000 +0x8000
lets:lo=(a:seed-0x80000000) % 0x10000
elselets:hi=a:seed / 0x10000 +0x8000
lets:lo=a:seed % 0x10000
endifendfunctionfunction!s:rand()ifs:hi==0lets:hi=s:random_seed()endififs:lo==0lets:lo=s:random_seed()endififs:hi<0lethi=s:hi-0x80000000
lethi=36969 * (hi % 0x10000)+(hi / 0x10000 +0x8000)elselethi=s:hilethi=36969 * (hi % 0x10000)+(hi / 0x10000)endififs:lo<0letlo=s:lo-0x80000000
letlo=18273 * (lo % 0x10000)+(lo / 0x10000 +0x8000)elseletlo=s:loletlo=18273 * (lo % 0x10000)+(lo / 0x10000)endiflets:hi=hilets:lo=loreturn(hi * 0x10000)+((lo<0 ? lo-0x80000000 :lo) % 0x10000)endfunctionfunction!s:random()letn=s:rand()ifn<0return(n-0x80000000)/ 4294967295.0 + (0x40000000 /(4294967295.0 / 2.0))elsereturnn / 4294967295.0endifendfunction" V8 uses C runtime random function for seed and initialize it with time.lets:seed= float2nr(fmod(str2float(reltimestr(reltime())) * 256,2147483648.0))function!s:random_seed()lets:seed=s:seed * 214013+2531011return(s:seed<0 ? s:seed-0x80000000 :s:seed) / 0x10000 % 0x8000
endfunction属性値が示す勾配を補正していく為に1をゲインとするシグモイド関数を用意します。よく見るこういう奴ですね。
h(x) = \frac{1}{1+e^{-x}}\\
function!s:add(x,y) abort
returnjoin(map(a:x,'v:val + a:y[v:key]'),'+')endfunctionfunction!s:scale(x,f) abort
return map(deepcopy(a:x),'v:val * a:f')endfunctionfunction!s:dot(x,y) abort
return eval(join(map(deepcopy(a:x),'v:val * a:y[v:key]'),'+'))endfunctionfunction!s:softmax(w,x) abort
letl:v=s:dot(a:w,a:x)return1.0 / (1.0+ exp(-l:v))endfunctionfunction!s:predict(w,x) abort
returns:softmax(a:w,a:x)endfunctionfunction!s:logistic_regression(X,y, rate, ntrains) abort
letl:w= map(repeat([[]], len(a:X[0])),'s:random()')letl:w=[0.1,0.2,0.3,0.4]letl:rate =a:rateforl:nin range(a:ntrains)forl:iin range(len(a:X))letl:x=a:X[l:i]letl:t= deepcopy(l:x)letl:pred =s:softmax(l:t,l:w)letl:perr =a:y[l:i]-l:pred
letl:scale =l:rate * l:perr * l:pred * (1.0-l:pred)calls:add(l:w,s:scale(l:x,l:scale))endforendforreturnl:wendfunctionl:perr * l:pred * (1.0 - l:pred)の部分でオッズ比を得て学習率(l:rate) からどの程度を次回の学習にデータを持ち越すかを決めます。なのでこの l:rateが大きいと予測結果が安定しない事になります。これを以下の様に実行すると、入力データに対するパラメータ wが得られます。
letl:w=s:logistic_regression(l:X,l:y,0.3,500)乱数を使っているので常に同じ値にはなりません。
[-0.346271, -0.52895, 0.600594, 0.724118]
Intel Core i5、16GB の PC で4秒程度です。試しに入力データの1行目を使ってこの wがどの様に働くかを確認します。
5.1,3.5,1.4,0.2,Iris-setosa
学習した内容と同じ事をすれば良いので wとこのベクトルの内積の和から得られる値のゲイン(上の predict)を得れば良い事になります。以下の様に実行します。
:echo s:softmax([-0.346271,-0.52895,0.600594,0.724118],[5.1,3.5,1.4,0.2])0.067129
これが上記で得た品種名の添え字(およそ 0 つまり iris-setosa)になる訳です。以下の様にすれば元の品種名に戻せます。
letl:ni = map(sort(map(keys(l:vocab),'[v:val, float2nr(l:vocab[v:val])]'),{a,b->a[1]-b[1]}),'v:val[0]')forl:xinl:X
letl:r=s:predict(l:w,l:x)
echo l:ni[min([float2nr(l:r * len(l:vocab)+0.1), len(l:vocab)-1])]endfor正解率を調べます。
letl:ni = map(sort(map(keys(l:vocab),'[v:val, float2nr(l:vocab[v:val])]'),{a,b->a[1]-b[1]}),'v:val[0]')letl:count =0forl:iin range(len(l:X))letl:x=l:X[l:i]letl:r=s:predict(l:w,l:x)ifl:ni[min([float2nr(l:r * len(l:vocab)+0.1), len(l:vocab)-1])]==l:data[l:i][4]letl:count +=1endifendfor
echo l:count
141と出たので、およそ 94% という所です。
学習データと検証データ
全てのデータを学習用に使ってしまうと「そりゃ正解率高いだろ」という結果になってしまうのでデータを学習用とテスト用に分けます。
function!s:shuffle(arr)letl:arr =a:arrletl:i= len(l:arr)whilel:iletl:i-=1letl:j=s:rand() * l:i % len(l:arr)ifl:i==l:j
continue
endiflet[l:arr[l:i],l:arr[l:j]]=[l:arr[l:j],l:arr[l:i]]endwhilereturnl:arr
endfunctionデータをシャッフルして120件を学習に、残り30件をテストとなる様に分割します。
letl:data = map(readfile('iris.csv'),'s:token(v:val)')[1:]calls:shuffle(l:data)let[l:train,l:test]=[l:data[:119],l:data[119:]]学習用の件数が減ったので学習率と学習回数も調整が必要です。
let l:w = s:logistic_regression(l:X, l:y, 0.1, 3000)
※要はまぁ、学習する為の入力データの1件1件をどれくらい大事にするかという話です。
0.967742
という、まぁまぁな正解率が得られました。
まとめ
Vim script で機械学習を扱いアヤメの品種を分類しました。Vim script は使えるけど Python をうまく扱えない人、宗教上の理由で Python が書けない人、色々いらっしゃるかと思います。Vim script なら分かるぞという方でもデータサイエンスが出来る事を伝えられたのではと思います。Vim script はエディタ上で動作するスクリプト言語です。実行しつつ編集したり、編集しつつ実行できる統合開発環境なのです。Vim script からデータサイエンスの世界に入ってみるのも良いかもしれません。
最後にソースコード全体を Gist に載せておきます。遊びたい方はどうぞ。
https://gist.github.com/mattn/920779ca764b777174958db0430964ae